Leakage and the Reproducibility Crisis in ML-based Science
We argue that there is a reproducibility crisis in ML-based science. We compile evidence of this crisis
across fields, identify data leakage as a pervasive cause of reproducibility failures, conduct our own
reproducibility investigations using in-depth code-review, and propose a solution.
Many quantitative science fields are adopting the paradigm of predictive modeling
using machine learning. We welcome this development. At the same time, as researchers whose interests include
the strengths and limits of machine learning, we have concerns about reproducibility and overoptimism.
There are many reasons for caution:
Performance evaluation is notoriously tricky in machine learning.
ML code tends to be complex and as yet lacks standardization.
Subtle pitfalls arise from the differences between explanatory and predictive modeling.
The hype and overoptimism about commercial AI may spill over into ML-based scientific research.
Pressures and publication biases that have led to past reproducibility crises are also present in
ML-based science.
Given these reasons, we view reproducibility difficulties as the expected state of affairs until best practices
become better established and understood. The spate of reproducibility failures (that we have compiled below)
highlights the immaturity of ML-based science, the critical need for ongoing work on methods and best practices,
and the importance of treating the results from this body of work with caution.
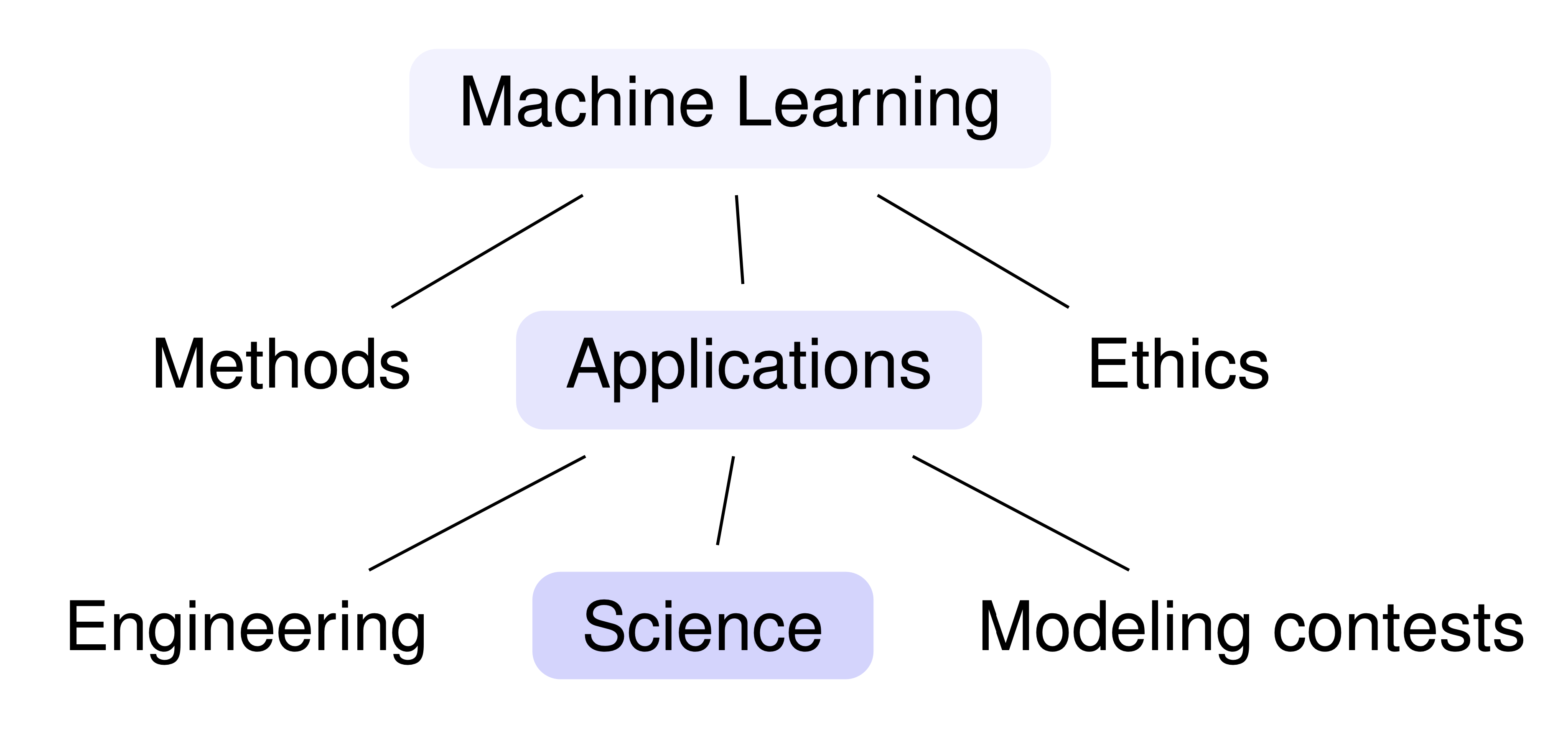
Scope
We focus on reproducibility issues in ML-based science, which involves making a scientific claim using the
performance of the ML model as evidence. There is a much better known reproducibility crisis in research that
uses traditional statistical methods. We also situate our work in contrast to other ML domains, such as
methods research (creating and improving widely-applicable ML methods), ethics research (studying the ethical
implications of ML methods), engineering applications (building or improving a product or service), and
modeling contests (improving predictive performance on a fixed dataset created by an independent third party).
Investigating the validity of claims in all of these areas is important, and there is ongoing work to address
reproducibility issues in these domains.
A non-exhaustive categorization of focus areas in ML literature. In our work, we focus on ML-based
science.
Why do we call these reproducibility failures?
The goal of predictive modeling is to estimate (and improve) the accuracy of predictions that one
might make in a real-world scenario. This is true regardless of the specific research question one
wishes to study by building a predictive model. In practice one sets up the data analysis to mimic
this real-world scenario as closely as possible. There are limits to how well we can do this and
consequently there is always methodological debate on some issues, but there are also some clear
rules. If an analysis choice can be shown to lead to incorrect estimates of predictive accuracy, there
is usually consensus in the ML community that it is an error. For example, violating the train-test
split (or the learn-predict separation) is an error because the test set is intended to provide an
accurate estimate of 'out-of-sample' performance — model performance on a dataset that was not used
for training. Thus, to define what is an error, we look to this consensus in the ML community (e.g. in
textbooks) and offer our own arguments when necessary.
Data leakage causes reproducibility failures in ML-based science
The running list below consists of papers that highlight reproducibility failures or pitfalls in ML-based
science. We find 41 papers from 30 fields where errors have been found, collectively affecting 648 papers and
in some cases leading to wildly overoptimistic conclusions. In each case, data leakage causes errors in the
modeling process. (Table updated in May 2024)
Pre-processing on training and test sets; Feature selection on training and test sets
Data leakage has long been recognized as a leading cause of errors in ML applications. In formative work on
leakage, Kaufman et al. provide an overview of
different types of errors and give several recommendations for mitigating these errors. Since this paper was
published, the ML community has investigated the impact of leakage in severalengineering
applications and modeling competitions. However, leakage occurring in ML-based science has not been
comprehensively investigated. As a result, mitigations for data leakage in scientific applications of ML
remain understudied.
Towards a solution: A taxonomy of data leakage
A taxonomy of data leakage can enable a better understanding of why leakage occurs in ML-based science and
inform potential solutions. We present a fine-grained taxonomy of 8 types of leakage that range from textbook
errors to open research problems. Our taxonomy is comprehensive and addresses data leakage arising during the
data collection, pre-processing, modeling and evaluation steps. In particular, our taxonomy addresses all cases
of data leakage that we found in our survey. We provide an overview of the types of leakage here, a more
detailed taxonomy is included in our paper.
1. Lack of clean separation of training and test set: If the training dataset is not separated from the
test dataset during all pre-processing, modeling and evaluation steps, the model has access to information in
the test set before its performance is evaluated.
2. Model uses features which are not legitimate: The model has access to features that should not be
legitimately available for use in the modeling exercise, for instance if they are a proxy for the outcome
variable.
3. Test set is not drawn from the distribution of interest: The distribution of data on which the
performance of an ML model is evaluated differs from the distribution of data about which the scientific claims
are made.
Model info sheets for addressing leakage
Our taxonomy of data leakage highlights several failure modes which are prevalent in ML-based science. To
address leakage, researchers using ML methods need to connect the performance of their ML models to their
scientific claims. To detect cases of leakage, we provide a template for a model info sheet which should be included when
making a scientific claim using predictive modeling. The template consists of precise arguments needed to
justify the absence of leakage, and is inspired by Mitchell et
al.'s model cards for increasing the transparency of ML models.
Model info sheets can be voluntarily used by researchers to detect leakage. Of course, model info sheets can’t
prevent researchers from making false claims, but we hope they can make errors more apparent. Note that for
model info sheets to be verified, the analysis must be computationally reproducible. Also, model info sheets
don’t address reproducibility issues other than leakage.
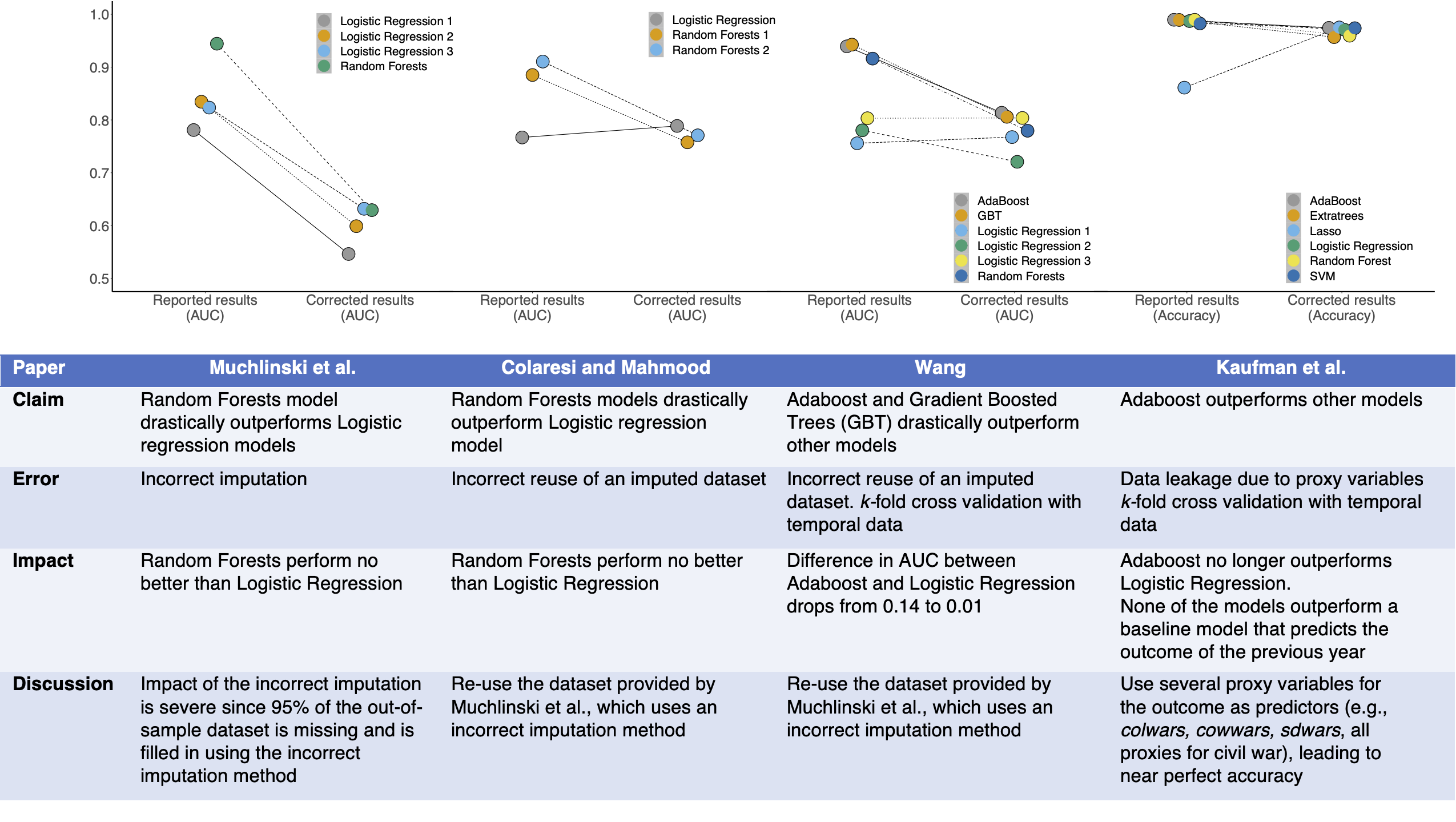
A case study of irreproducibility in civil war prediction
We find that prominent studies on civil war prediction claiming superior performance of ML models over
baseline Logistic Regression models fail to reproduce. Our results provide two reasons to be skeptical of the
use of ML methods in this research area, by both questioning their usefulness and highlighting the pitfalls of
applying them correctly. While none of these errors could have been caught by reading the papers, our model
info sheets enable the detection of leakage in each case.
A comparison of reported and corrected results in civil war prediction papers published in top Political
Science journals.
The main findings of each of these papers are invalid due to various forms of data leakage:
Muchlinski et al. impute the training and test data together, Colaresi & Mahmood and Wang incorrectly
reuse an imputed dataset, and Kaufman et al. use proxies for the target variable which causes data
leakage. The use of model info sheets would detect leakage in every paper. When we correct these errors,
complex ML models (such as Adaboost and Random Forests) do not perform substantively better than
decades-old Logistic Regression models for civil war prediction in each case. Each column in the table
outlines the impact of leakage on the results of a paper.
We acknowledge that there isn't consensus about the term reproducibility, and there have been a number of
recent attempts to define the term and create consensus. One possible definition is computational
reproducibility — when the results in a paper can be replicated using the exact code and dataset provided by
the authors. We argue that this definition is too narrow because even cases of outright bugs in the code would
not be considered irreproducible under this definition. Therefore we advocate for a standard where bugs and
other errors in data analysis that change or challenge a paper's findings constitute irreproducibility. We
elaborate this perspective here.
Reproducibility failures don’t mean a claim is wrong, just that evidence presented falls short of the accepted
standard or that the claim only holds in a narrower set of circumstances than asserted. We don’t view
reproducibility failures as signs that individual authors or teams are careless, and we don’t think any
researcher is immune. One of us (Narayanan) has had multiple such failures in his applied-ML work and expects
that it will probably happen again.
We call it a crisis for two related reasons. First, reproducibility failures in ML-based science are systemic.
In nearly every scientific field that has carried out a systematic study of reproducibility issues, papers are
plagued by common pitfalls. In many systematic reviews, a majority of the papers reviewed suffer from these
pitfalls. Second, despite the urgency of addressing reproducibility failures, there aren’t yet any systemic
solutions.
Our interest in this topic arose during a graduate
seminar on Limits to Prediction. Narayanan offered this course together with Prof. Matthew Salganik in
Fall 2020, and Kapoor took the course. The course aimed to critically examine the narrative about the ability to
predict the future with ever-increasing accuracy given bigger datasets and more powerful algorithms. The work on
reproducibility pitfalls is one aspect of our broader interest in limits to prediction.